




































软件介绍
Ultimate Vocal Remover是一款功能强大的音频处理工具,软件可帮助用户对音频进行处理,剔除音频中的人声,获取最干净的伴奏。软件功能强大,有着丰富多样的功能和处理模型,可针对不同类型的音乐提取伴奏。软件支持调用显卡强大的运算能力,帮助用户快速的完成伴奏的提取。
安装方法
(1) CUDA安装(有英伟达显卡的可以安装)
直接双击.exe文件运行即可,比如我用的cuda文件是cuda_11.6.0_511.23_windows.exe,直接双击运行。
安装的时候选自定义(高级),安装所有组件。
对于11.6版本的cuda,我是没有配置任何环境变量就可以成功的
验证是否成功的方法:新打开一个cmd窗口,在cmd窗口中输入nvcc -V,有正确输出即可

(2) 安装Python
直接以管理员运行python-3.9.8-amd64.exe即可,选择"Customize installation",一定要把“Add Python 3.9 to PATH”勾选上,安装的目标路径不要选C盘,安装到其他任何一个盘就可以
为了方便后续的解释,我们假设Python全部都安装到D:\Python文件夹中,D:\Python\bin\中有python.exe(python程序)和其他文件。
安装完之后,打开cmd窗口(Win键+R,然后输入cmd),输入python之后有相关显示即可,类似如下显示
(3) 安装ffmpeg
直接解压安装包,然后将安装包下的bin的绝对路径添加至环境变量中的"Path"变量中,
要确保安装完之后,在cmd窗口中输入ffmpeg是有输出的,记得配置完环境变量之后要重新打开cmd窗口再试命令
(4) 安装主程序
解压主程序安装包和模型安装包,解压后主程序的文件夹(ultimatevocalremovergui-master)下会有一个文件夹名为models,将模型安装包中的所有模型文件(后缀名为.pth的文件)都放到models文件夹下的Main Models文件夹中
为了方便后续的解释,这里我们假设主程序都解压到D:\ultimatevocalremovergui-master中,ultimatevocalremovergui-master目录下有VocalRemover.py文件和其他文件;模型文件全部都在"D:\ultimatevocalremovergui-master\models\Main Models"中
(5) 安装Python依赖包
a.安装virtualenv
首先在cmd窗口中,输入"pip install -i https://pypi.tuna.tsinghua.edu.cn/simple virtualenv"
使用cmd切换到在主程序的目录下(切换命令:cd /d D:\ultimatevocalremovergui-master),输入"virtualenv -p python.exe的绝对路径 venv\",比如"virtualenv -p D:\Python\bin\python.exe venv\"
接下来切换到venv\bin目录下(切换命令:cd /d venv\Scripts),输入"activate"并回车
完成这步之后,命令前面都会带着(venv)这个标志,请确保后面的所有的操作(安装以及运行)都需要在执行这一步之后

b.安装程序的依赖包
在cmd窗口中,输入"pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --no-cache-dir -r requirements.txt"并回车
c.安装pytorch组件
在cmd窗口中,输入"pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html"并回车
(因为众所周知的原因,在国内可能是安装不了的)
或者
如果前面已经下载了Pytorch组件,可以按照如下步骤安装:
切换到那三个文件目录下
分别执行如下三个命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torch-1.9.0%2Bcu111-cp39-cp39-win_amd64.whl
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torchvision-0.10.0%2Bcu111-cp39-cp39-win_amd64.whl"
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torchaudio-0.9.0-cp39-cp39-win_amd64.whl"
运行程序:
确保目前是(venv)状态
如果目前没有这个标志,可重新在cmd窗口中输入"D:\ultimatevocalremovergui-master\venv\Scripts\activate"并回车
在cmd窗口中切换到VocalRemover.py所在目录(cd /d D:\ultimatevocalremovergui-master)
执行如下命令
python VocalRemover.py

即可进入主程序
PS:每次执行都需要确保是(venv)状态
作者:明沙
出处:bilibili
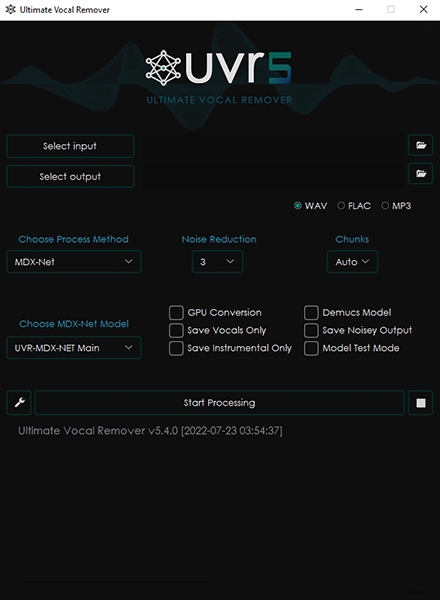
使用说明
Select Input:选择(多个)文件
Select Output:输出目录,希望可以保存消音后的文件的地方
Open Input Folder Button:打开包含选择的音频文件的目录
Open Output Folder Button:打开输出目录
Choose Process Method:
选择消音方法——三种选项。
(1) VR Architecture:使用了强度频谱(magnitude spectrogram)或源分离(Source Separation)的模型
(2) MDX-Net:使用了混合频谱/波形(Hybrid Spectrogram/Waveform)用于源分离的模型
(3) Ensemble Mode:融合模式,可以得到多个模型和网络的最好结果
Help/Info Button:帮助引导(help guide)
Choose MDX-Net:每个消音方法都有自己的一套选项和模型,在这里可以选择与所选消音方法关联的模型
Progress Console:显示处理过程中的信息
Restart Button:重启应用,会弹出来窗口缺人,所有设定(settings)都会被保存
Save Format:输出格式选择(WAV、FLAC、MP3)
GPU Conversion:勾选即可使用GPU加速(有英伟达显卡并安装了cuda的人选)
如果不勾选的话,只用CPU处理会很慢
Demucs Model:Demucs是Facebook开源的声音分离模型,这功能我还没试过,试用之后修改这部分
Save Vocals Only:只保存人声(Vocals)文件,即不保存伴奏文件
Save Instrumental Only:只保存伴奏(instrumental)文件,即不保存人声文件
Save Noisey Vocal:保存噪音,这部分我还没试过,试用之后修改这部分
Model Test Mode:模型试用模式,选择了这个模式的时候, 程序会自动在你选择的文件夹里面生成一个新文件夹。新的自动生成文件夹将以所选模型命名(不再是上述的默认命名)。输出的音频文件将保存到自动生成的目录中。
乐器和人声输出的文件名将附加选定的模型名称,避免了测试多个模型而造成覆盖的问题。
VR Architecture
Windows Size:
窗口大小越小,转化效果越好。然而,更小的窗口意味着更长的转换时间和更重的资源使用。
以下是可选择的窗口大小值 -
1024 - 转换质量低,转换时间最短,资源使用率低
512 - 平均转换质量、平均转换时间、正常资源使用情况
320 - 转换质量更好,转换时间长,资源使用率高
Aggression Setting:
数值越大,清除人声的力度就越大,默认的10就可以,已经可以完全消除人声
范围是 0-100
较高的值执行更深的提取
乐器和声乐模型的默认值为 10
超过 10 的值可能会导致抽取伴奏的模型的结果中的乐器部分听起来浑浊
TTA:测试时数据增强,用于提升分离效果,但是会增加处理时间
Post-Process:此选项可能会识别人声输出中剩余的乐器伪影。此选项可能会改善某些歌曲的分离效果。
注意:选择此选项可能会对转换过程产生不利影响,具体取决于轨道。因此,仅建议作为最后的手段
Chunks:允许用户减少 (或增加)RAM(内存)或V-RAM的使用率。
更小的Chunk sizes会使用更少的内存或显存但是会增加处理时间
更大的Chunk sizes会使用更多的内存或显存但会减少处理时间
选择Auto的话程序会自动计算合适的Chunk sizes
选择Full会直接处理整个轨道,这个选项只推荐用在比较强力的PC上
默认值是Auto
Noise Reduction:该选项允许减少或消除由模型产生的任何噪音
灵敏度的值范围是0到20,默认是3,选择None会关闭Noise Reduction这个选项
模型:
UVR-MDX-NET 1:模型分数9.703
UVR-MDX-NET 2:模型分数9.682
UVR-MDX-NET 3:模型分数9.662
UVR-MDX-NET Karaoke:保留和声模型
PS:模型分数指的是SDR score
MDX-Net/VR Ensemble:
通过UVR_MDXNET_1和2_HP-UVR.pth这两个模型生成结果并融合
HP Models:
通过1_HP-UVR.pth和2_HP-UVR.pth这两个模型生成结果并融合
Vocal Models:
通过3_HP-Vocal-UVR.pth和4_HP-Vocal-UVR.pth这两个模型生成结果并融合
User Ensemble:
允许用户选择不同模型的输出结果并手动将它们融合
HP2 Models:
通过7_HP2-UVR.pth、8_HP2-UVR.pth和9_HP2-UVR.pth这三个模型生成音频文件并融合
All HP Models:
使用1_HP-UVR.pth、2_HP-UVR.pth、7_HP2-UVR.pth、8_HP2-UVR.pth和9_HP2-UVR.pth这五个模型生成音频文件并融合
Save All Outputs:输出所有模型的结果,不选就不会输出,只会保留融合后的结果
Select input:至少选择两个模型生成的消音后的音频文件
Select output:选择输出目录
Dropdown:选择算法:
Instrumentals(Min Spec):读取输入的音频文件的频谱,并且计算每个输入文件的最小spec值,结果文件中的vocal数据会被清除
生成文件的后缀名:_User_ensembled_(Min Spec).wav
Vocals(Max Spec):读取输入的以您文件的频谱,并且计算每个输入文件的最大spec值,结果文件中所有的vocal数据都会被保留
生成文件的后缀名:_User_ensembled_(Max Spec).wav
作者:明沙
出处:bilibili
主要模型说明
HP2_3BAND_44100_MSB2.pth - 使用更多数据和更多参数训练的超强消人声保留伴奏模型(PS:理论上数据越多训练出来的模型效果越好)
HP2_4BAND_44100_1.pth - 超强消人声保留伴奏模型
HP2_4BAND_44100_2.pth - HP2_4BAND_44100_1.pth的微调版本
HP_4BAND_44100_A.pth - 超强消人声保留伴奏模型
HP_4BAND_44100_B.pth - HP_4BAND_44100_A.pth的微调版本
HP_KAROKEE_4BAND_44100_SN.pth - 可保留和声的消主声伴奏模型
HP_Vocal_4BAND_44100.pth - 人声提取模型,但是提取的伴奏会比较muddy
HP_Vocal_AGG_4BAND_44100.pth - HP_Vocal_4BAND_44100.pth 的加强版,这个强的意思不是效果好,是Aggressive的人声提取模型
配置要求
建议使用至少8GB 显存的英伟达(Nvidia)GPU
该程序只与64位平台兼容
该程序依赖Sox - Sound 交换用于噪音消除
该程序依赖FFmpeg处理非wav格式的音频文件
该程序会在你关闭程序的时候自动保存你的设置
处理效率极大依赖于你的硬件
如果未安装 FFmpeg,如果用户尝试转换非 WAV 文件,应用程序将抛出错误。






网友评论